
Camunda BPM is open source, you can download the distribution from camunda.com and inspect the sources on GitHub.
Highlights of 7.2.0 Final
New Tasklist
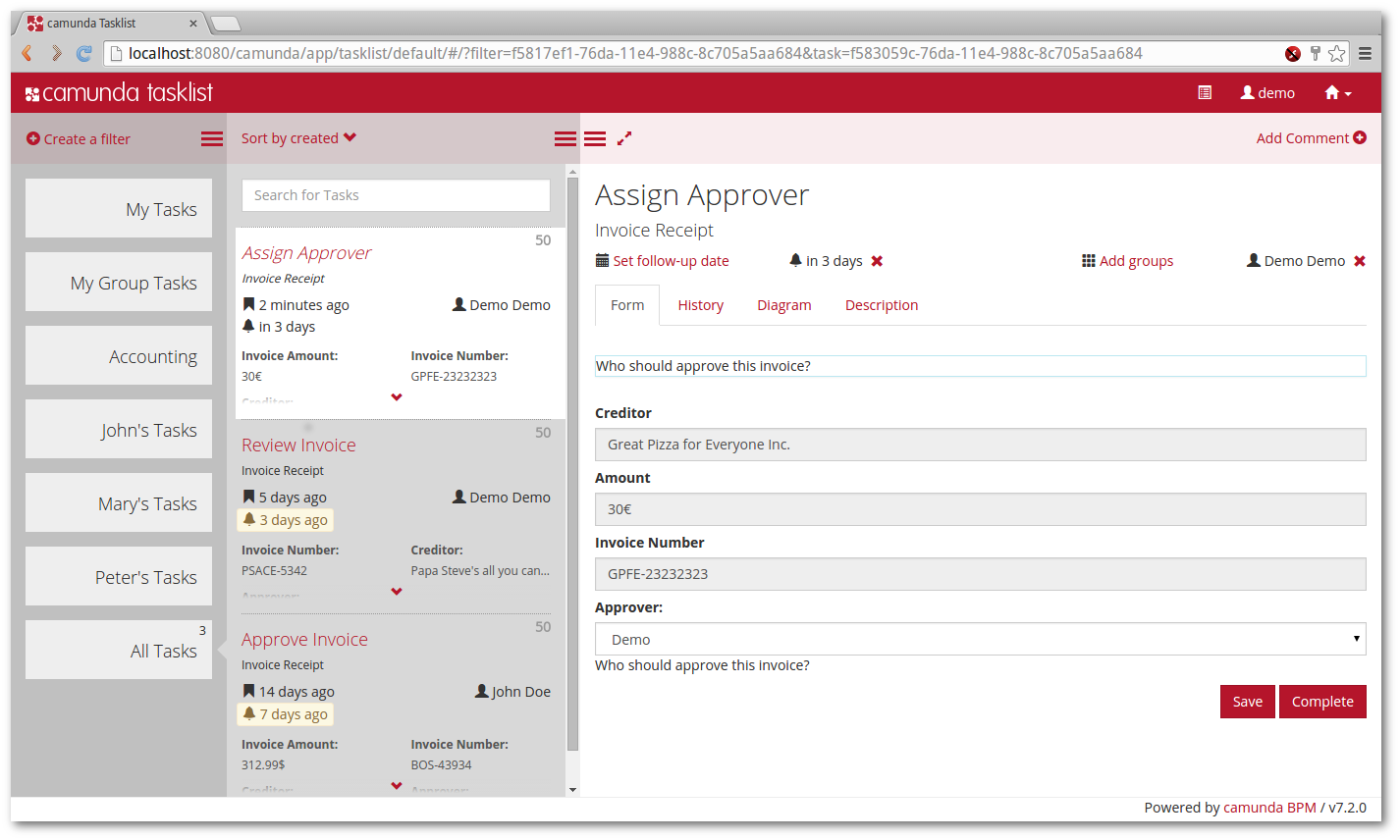
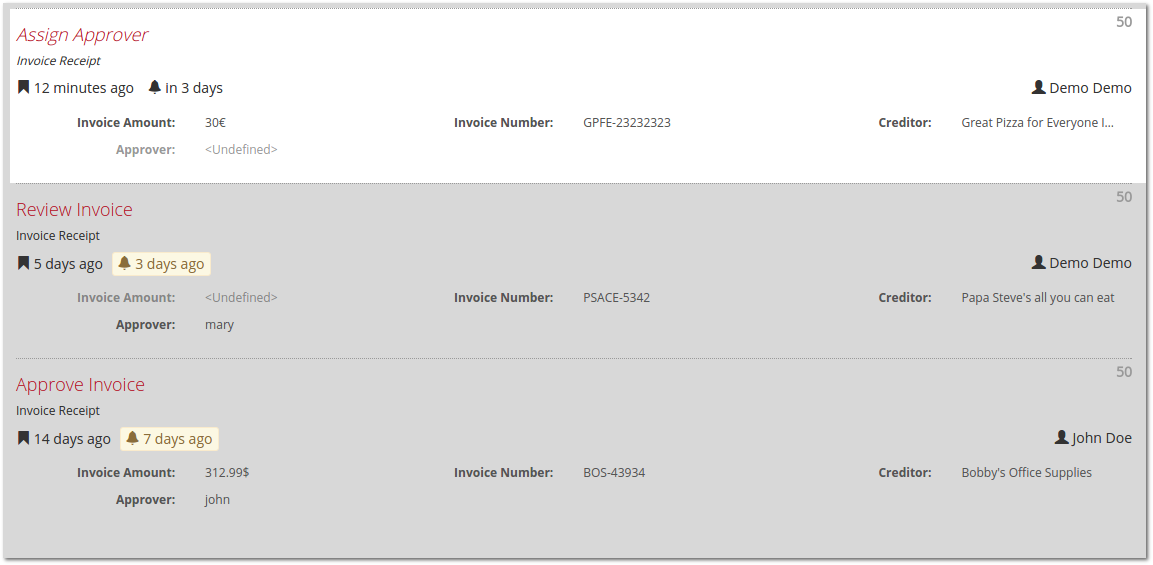
The Tasklist layout is divided into three columns: a configurable list of filters, a list of tasks and the task details. Each column can be collapsed: for instance, once you have selected a filter, you can collapse the left column and focus on the list of tasks or an individual task. The task view itself can be maximized which gives more room for complex forms.
Task Filters represent Task Queries (which some of you may know from using the Java API or the REST API of the process engine) which are saved to the database such that they can be executed repeatedly. Filters can be configured directly inside the Tasklist:
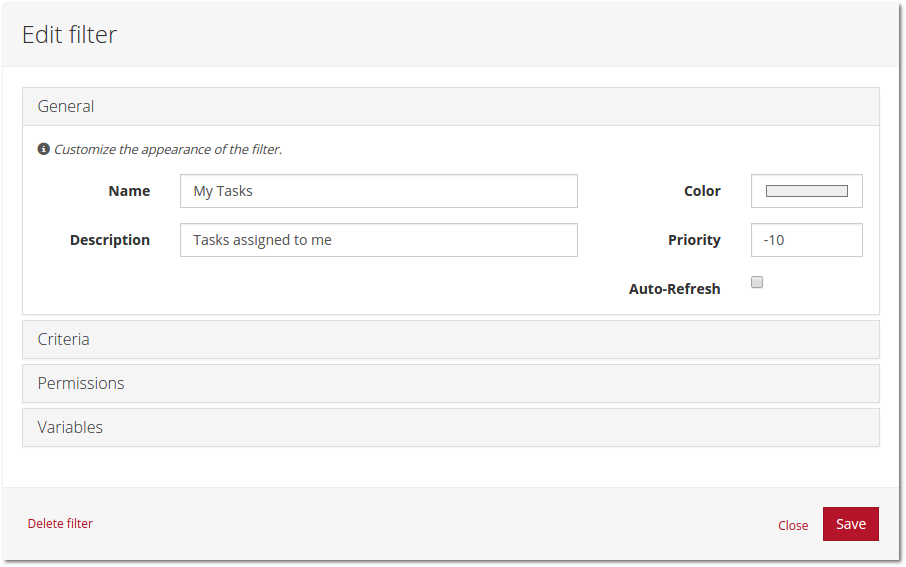
The above image shows the “General” settings of a filter. A filter can be assigned a name, a description as well as a color and a priority (which determines the ordering in the list of filters). The “Auto refresh” setting is interesting: if it is enabled, the filter is periodically refreshed such that users of the Tasklist notice if a task is added or removed by another user or the process engine.
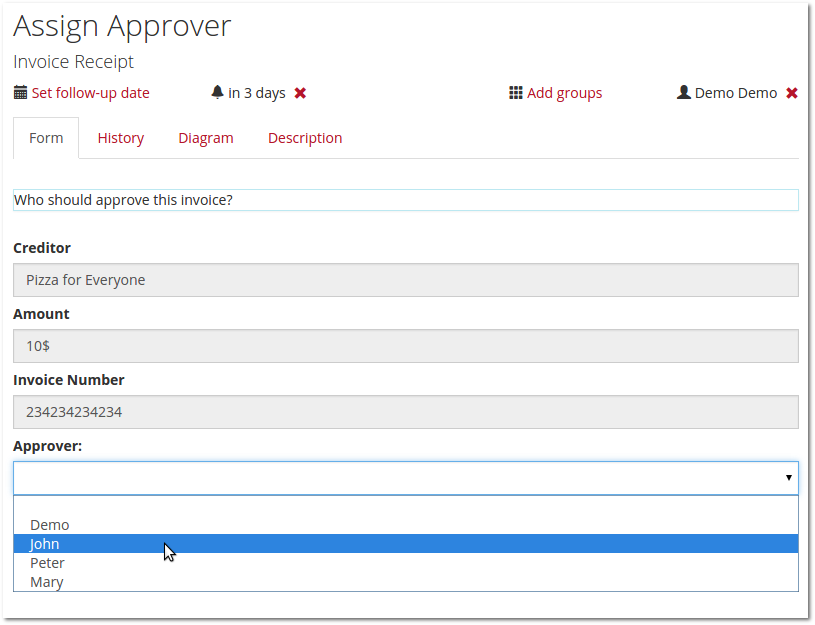
It is also possible to define the criteria of the filter (which represent the actual task query):
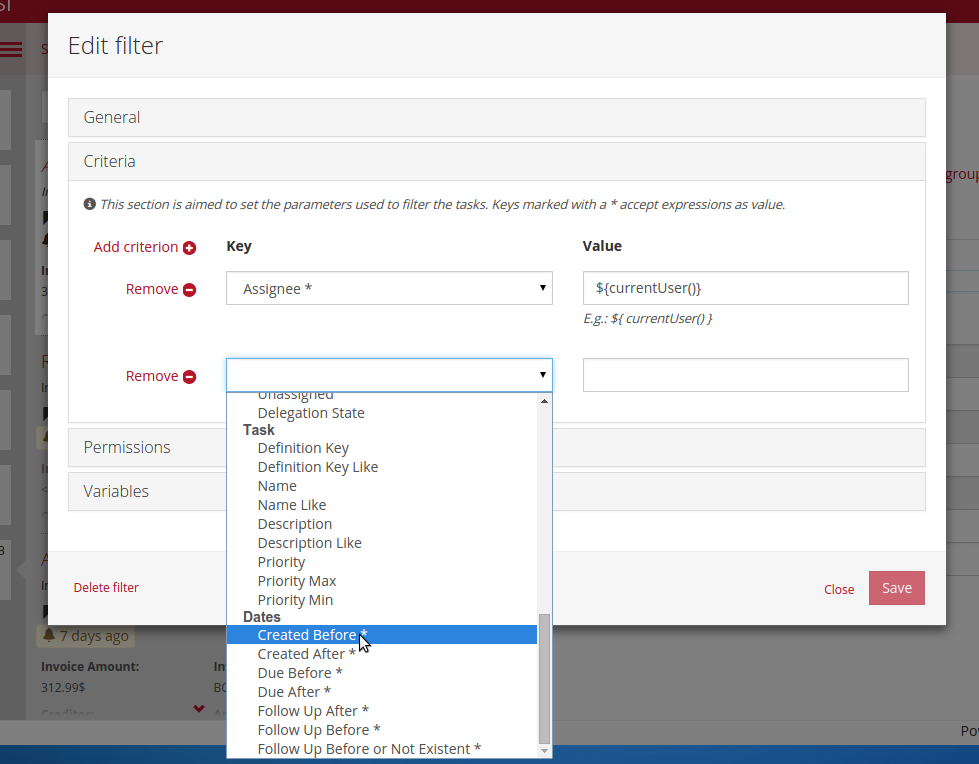
Filters (and the task query itself, for that matter) now also support expressions which make the filters more flexible and usable by multiple users. Check the user guide for a list of useful expression language additions for filters.
We put in place a sophisticated authorization system for filters: first, you can configure which users and groups are authorized to create new filters. Users who are authorized to create filters can then share these filters with either all other users (globally) or with defined users and groups. This way users can determine which filters other users can see inside the Tasklist and by extension, which kinds of tasks these other users should work on.
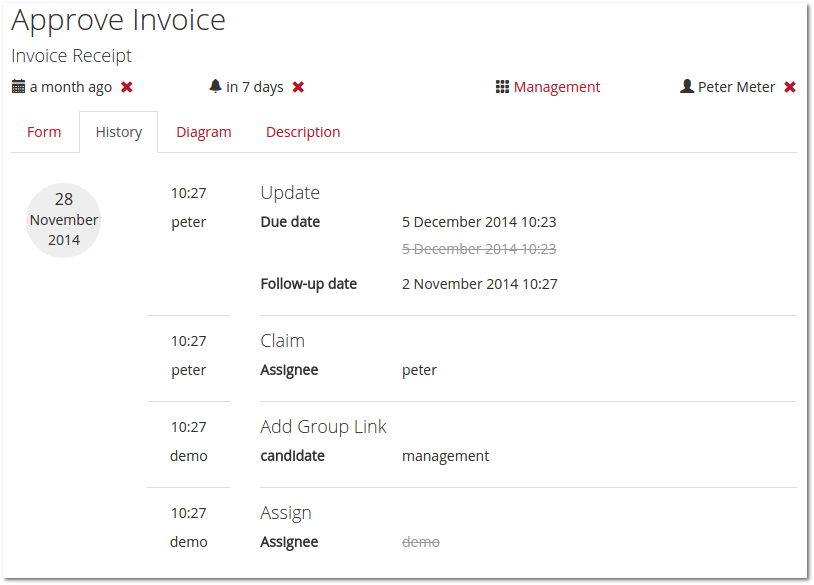
Finally, it is also possible to configure a list of variables which should be fetched and displayed in the list of tasks:
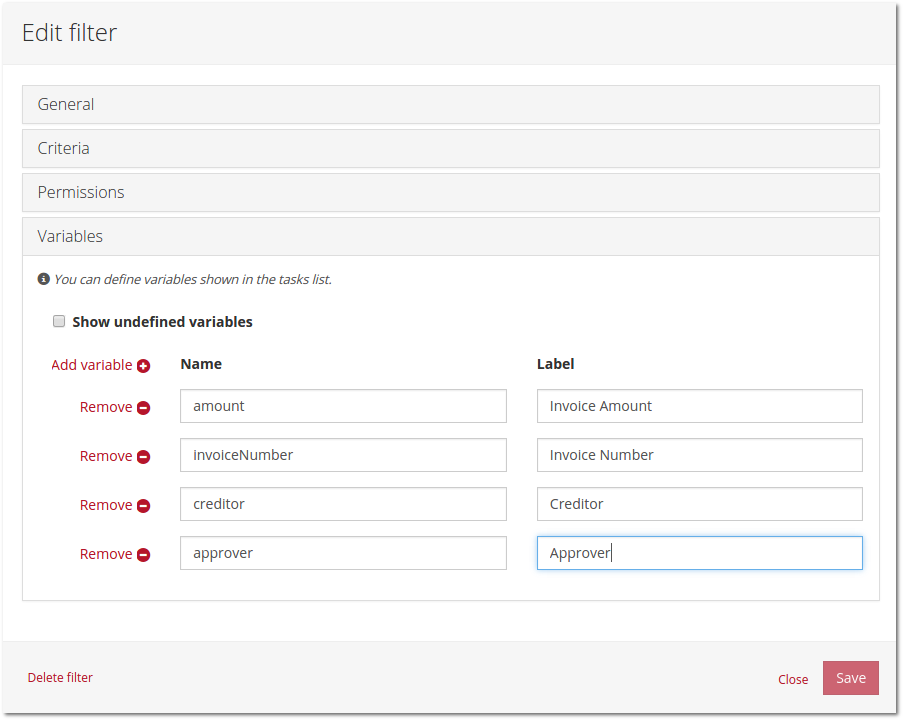
The result is that these variables are fetched for all tasks matched by the filter:
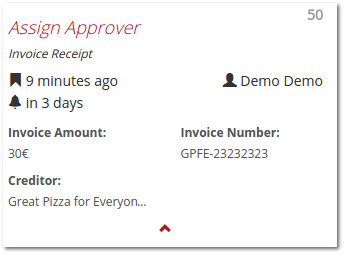
Besides the variables, the “task cards” in the list of tasks provide the following information:
Case Management with CMMN
CMMN allows modeling Cases. A case allows humans to do work in a more or less structured way in order to achieve something. Classic examples where case management is applied are Credit Application, Customer Support Management, Document Management, and so on.
The following is a simple Example of a Credit Application Case modeled in CMMN:
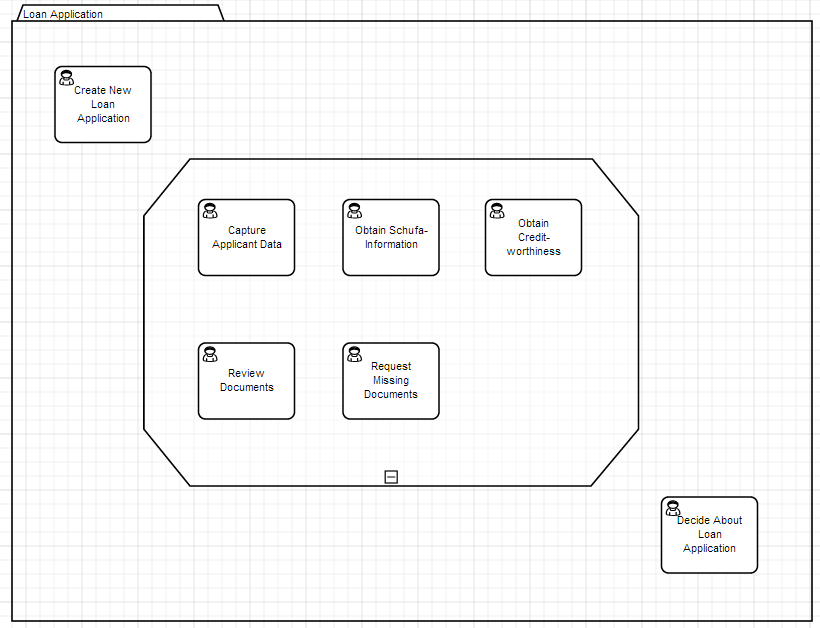
- Stage
- Human Task, Process Task, Case Task
- Sentries
- Milestones
The implementation is provided through the process engine Java API as well as the REST API.
Process Engine Improvements for High Load Scenarios
- Reduction of dead locks due to consistent flush ordering. Before, the ordering of the database flush (INSERTS, UPDATES, DELETES) at the end of the transaction could lead to deadlocks, the new implementation enforces that any two transactions working on the same pair of entities will flush modifications in the same order.
- 1st level cache reuse: the first level cache will always be consistent with the database at the end of a transaction which allows us to reuse it in subsequent transactions. The cache can currently be reused in sequences of asynchronous continuations executed by the Job Executor. At the end of a transaction we flush the deltas and then reuse the cache in the next transaction, instead of throwing the memory state away and re-fetching everything from the database. This makes asynchronous continuations a lot more light-weight.
- In the future:
- it may be easier to support alternative databases such as Mongo DB. We already experimented with Hazelcase (in-memory data grid) as persistence provider and it worked out.
- we will be able to remove the limitation induced by the fact that atomic operations are executed recursively: the stack size grows limiting the number of activity instance which can be executed in a single transaction. We could now remove this in the next release if users should need this.
Next, the scalability of the Job Executor (responsible for asynchronous processing) has been improved in 7.2. Before only 1-2 nodes could consume effectively from the queue, now users can now have larger clusters.
Custom history levels: it is now possible to implement a custom history level which allows users to determine in a very fine granular way what data should be logged. This is useful for users with extreme amounts of process instances and who need to control the number of history events produced.
Xml, JSON and other Dataformats
The serialization dataformat can be configured using the new, typed variable API:
CustomerData customerData = new CustomerData();
execution.setVariable("customerData", objectValue(customerData)
.serializationDataFormat(SerializationDataFormats.JSON)
.create());
We also introduce the Spin Dataformat API which provides support for parsing, writing, querying and mapping Xml and JSON data. The Spin Dataformat API can be used in Expression Language as well, allowing users to directly execute XPath or JsonPath when configuring sequence flow conditions:
${XML(customer).xPath("/customer/address/postcode").element().textContent() == "1234"}
The Spin Dataformat API allows users to extend it with custom functionality or implement their own dataformats. Source code for the Spin Dataformat API is available on GitHub.
Improved Scripting & Templating
- Compilation: the process engine can be configured to compile (and cache the compiled scripts) these languages. This improves performance.
- Scripts can now be used everywhere where expression language or custom Java code can be used, including Execution Listeners, Task Listeners, Sequence Flow conditions.
Out of the box REST and SOAP Connectors
What makes connectors different from plain Java delegate implementations (which you already know)?
- The most important difference is that connectors declare their input / output parameters. This will make it possible for us to build tooling which allows users to configure the input / output parameters of arbitrary connectors. Connector I/O is configured using variable I/O mapping (also new 🙂 )
- Connectors provide a simple Interceptor API which allows users to customize connectors. This way they can implement cross cutting concerns such as logging, authentication, encryption etc.
- Connectors provide a more Request / Response oriented API. We may also support asynchronous connectors in the future.
WildFly Application Server
Upgrading to 7.2.0 Final
Enterprise Support
The 7.2 release is the basis for the next supported production release for Camunda BPM. It is fully supported in the Camunda BPM enterprise subscription. Support includes Help Requests based on different SLAs as well as access to Camunda BPM maintenance releases. Maintenance releases allow customers to get bugfixes for production systems based on the 7.2 codebase. While the community project will forge ahead for 7.3, we will backport bugfixes to the 7.2 branch and perform maintenance releases reserved for enterprise subscription customers.
There is a Migration Guide targeting existing Camunda BPM 7.1 installations.
Join the Release Webinars
Community
Finally I want to thank the community for the awesome contributions we keep getting, both in the form of bug fixes and improvements to the main code base as well as community extension projects.
What’s Next?
- We will release Camunda Cycle 3.1 providing support for Git connector (among others) and better extensibility.
- The documentation will be improved, including chapters on Multi Tenancy
- And after that: Camunda BPM 7.3 🙂