
Jorn Horstman, André Hartmann and Lukas Niemeier from Zalando Tech visited us yesterday evening to present their prototype for running Camunda engine on Apache Cassandra.
They published their slides.
Zalando is a “multinational e-commerce company that specializes in selling shoes, clothing and other fashion and lifestyle products online“. 2014 they had a revenue of €2.3 billion and currently have 8,500 employees (Source: Wikipedia). AND: they are Camunda enterprise edition subscribers and use Camunda process engine for processing their orders. Whenever you buy something in their online shop, a process instance is kicked off in Camunda process engine.
Zalando’s current Architecture
Zalando’s system needs to scale horizontally.
Currently Zalando’s order processing runs on PostgreSQL database. They partition their order and process engine data over 8 Shards. Each shard is an independent instance of PostgreSQL. Such an “instance” is a small cluster with replication for performance and failover.
At the application server level they run on Apache Tomcat and use the Spring Framework. For each shard, they have a datasource for which they create an instance of camunda process engine. This is replicated over 16 nodes. When a new order comes in, it is assigned to one of the shards and an entry is made in a global mapping table, mapping orderIds to shards. Then the corresponding process instance is stated in that shard.
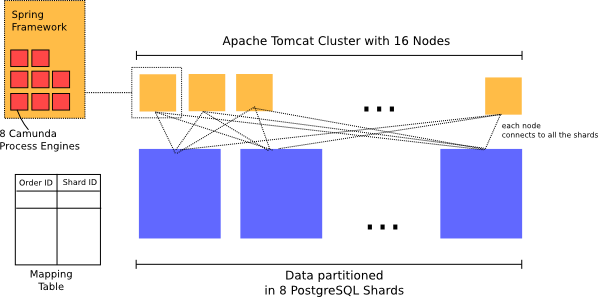
When messages come in, they are first correlated to an order. When the order is resolved, they can deduce the responsible shard for the order and resolve the corresponding process engine.
They say that this works quite well but has some drawbacks:
- They need to implement the sharding themselves,
- The mapping table needs to be maintained,
- Queries must be done against all of the shards and data must be aggregated manually.
In the context of their “Hackweek”, they looked into Apache Cassandra as an alternative.
The Cassandra Prototype
Over the course of a week, they built a prototype where they exchanged the relational DB persistence layer in Camunda with an alternative implementation based on Cassandra.
They say that they wanted to
- Learn more about Cassandra
- Get a better understanding of the Camunda DB structure
Their Goal was not to run this in production (yet).
They provide an alternative implementation of Camunda’s PersistenceSession interface.
In their prototype, they replicated Camunda’s relational model in Cassandra. They had a table for executions in which each execution became a row, they had tables for variables, tasks etc. They did this on purpose since they wanted to start with a naïve implementation and then learn from that.
During development they used a setup where they multiplexed the persistence session and executed all statements both on an SQL database and Cassandra in order to be able to enhance support progressively while always having a working system.
As a result, they can execute simple processes.
Lessons Learned
After they presented their prototype, we discussed the lessons learned. We focused on the core process execution use case, not on complex monitoring or task queries and things like that, assuming those use cases could be implemented on top of a dedicated search database such as elasticsearch into which data in fed from the execution cluster in near real time.
- Copying the relational data model is problematic. A single process instance is composed of many entities, if they are stored as multiple rows in different tables,
- Data related to a single process instance is distributed across the cluster. This does not match the process engine’s access pattern: often all data related to a process instance must be read or updated. If data is distributed, the network overhead is considerable.
- Without transactional guarantees we cannot make changed to multiple rows in different tables atomically.
- Eventual consistency: Cassandra keeps multiple copies of a data item. When making changes, you can configure whether you want to wait for all copies of a particular data item to be updated or whether one of the copies is enough or whether you need something in between (quorum, etc…). After some discussion, we concluded that the process engine would require to update all copies with most write operations.
It would be better to keep data related to a single process instance together in one row inside a single table. Then we could update it atomically, reading and updating it would entail minimal network overhead. In addition, we could require write operations to wait for all copies of the data they change to be updated.
From this the following model results:
- Data of a single process instance is kept in one row.
- If the process engine does an update to the row, it must first lock it. Conceptually, this could be a logical lock based on a retry mechanism.
- If the row is updated / deleted, the operation must be performed on all updates. (Forfeiting the A in the context of P).
Consequences: No intra-process instance concurrency (concurrency inside a single process instance) involving different process engine instances (a single process engine can still lock the row, do things in multiple threads, join the operations and do one atomic update, releasing the lock).
Discussing all of this was a lot of fun! More Meetings are scheduled