
Setting: Clustered Job Execution
As pointed out in the previous post on our new job prioritization feature, Camunda is widely used by customers in domains where the degree of automation is high, such as insurances or telecommunications. Being nation-wide or even world-wide players, these businesses handle large amounts of process instances and therefore need a BPM platform that scales with their demands. Prior to developing job prioritization we asked customers and community users in a survey to voice their requirements for job processing. In terms of load numbers, we learned that:
- Users process up to 1 million jobs per day.
- Camunda BPM is used in clusters of up to 20 nodes.
When setting up a cluster of Camunda BPM nodes, the simplified architecture looks as follows:
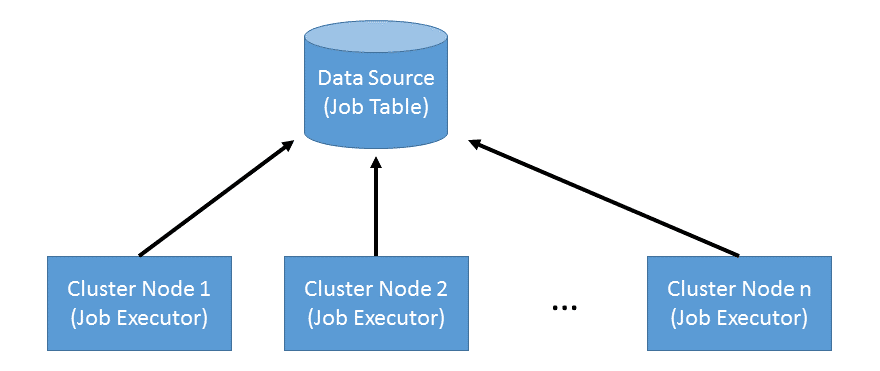
There is a central data source that a number of nodes responsible for executing BPMN processes access (side note: we talk about one logical data source; you can still apply replication on database level and horizontal partitioning of process instances to multiple databases). Cluster nodes are not coordinated by a central managing instance or in a peer-to-peer fashion. Instead data is exchanged via the central data source only. Each node runs a job executor instance that continuously polls the central data source for jobs to execute. One such cycle of job acquisition consists of the following steps:
- Select jobs from the job table that are executable (e.g. timer events must be due) and that are supposed to be executed next (e.g. when using job priorities).
- Lock jobs for execution by updating them with a timestamp in the future and a lock owner id. The timestamp guarantees that until it expires no other job executor attempts to acquire, lock, and execute the job.
- Submit the successfully locked jobs for execution to a thread pool.
Problem: Parallel Job Acquisition
As pointed out above, cluster nodes are not actively managed and coordinated. While this makes for a simple architecture in which nodes can be easily added and removed from the cluster, the individual nodes are unaware of each other and in particular acquire jobs independently. That means, two cluster nodes may execute the acquisition cycle in parallel and may select the same jobs during step 1. At step 2, every job can only be locked by only one node. Other parallel locking attempts fail due to the process engine’s optimistic locking mechanism. However, this also means that in the worst case an entire acquisition cycle is wasted without locking any jobs.
Let us call this the dining job executors: Executable jobs are like candy in a jar on a table. We want each job executor to take a fair share of sweets in an efficient way. However in the current state, job executors continuously claim to take sweets that were already taken in parallel.
We can examine this behavior in practice as well. We set up a Postgres 9.4 database on 2 cores of a 4 GHz machine and three execution nodes using Camunda BPM version 7.4.0-alpha1 running on a different host. We start 50,000 process instances that consist of a single asynchronous continuation resulting in 50,000 jobs ready for execution. We configure each job to artificially execute for 0 to 160 milliseconds which should roughly be in the range of invoking an external system. In addition, we use the new job prioritization feature and assign each job a random priority. The following graph shows the acquisition performance of a single execution node:
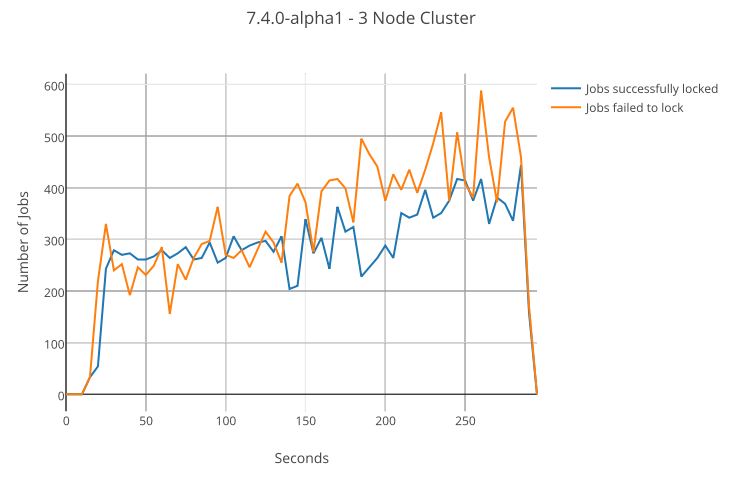
The graph shows the number of jobs acquired successfully (blue line; steps 1 and 2 of job acquisition succeed) as well as the jobs acquired but failed to lock (orange line; step 1 succeeds, step 2 fails). Already in a cluster of three nodes, we notice that the total number of jobs failed to lock outweighs the number of successfully acquired. This effect becomes worse the larger the cluster grows: When one node acquires jobs, it becomes more likely that any other node acquires the same jobs in parallel and succeeds locking them. While this behavior is not harmful for correct process execution, it wastes execution time and puts additional load on the database.
Improvement: Exponential Backoff
To avoid conflicts when locking jobs in steps 1 and 2 of acquisition, overlapping acquisition cycles need to become less likely. This can be done in two ways: First, the time a single cycle takes can be reduced. Second, the interval of cycles can be extended. We followed the second approach to which one solution is exponential backoff. The idea of backoff is that in case of failure to lock jobs a job executor waits for a certain amount of time before performing the next acquisition cycle. In case locking fails continuously the wait time increases exponentially. The number of jobs acquired increases with every increase in wait time as well. This way job acquisition becomes less frequent and ideally a configuration in which all job executor nodes acquire at different, non-overlapping times is reached.
Again, let us look at an example from practice. In the same cluster setup as before using the latest SNAPSHOT build, we use a backoff configuration with 30 milliseconds initial backoff and 150 milliseconds maximum backoff. Backoff increases by factor 2. Accordingly, the number of jobs acquired per cycle goes from 3 to 48. The resulting graph for one cluster node is:
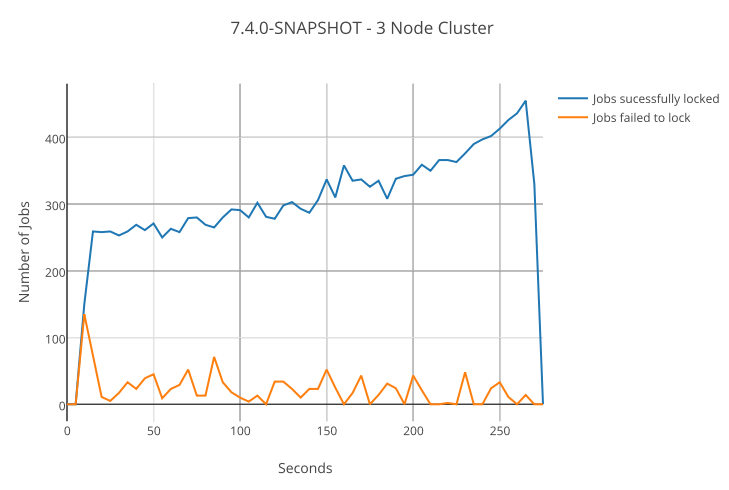
While acquisition failures are still present, they are much less frequent than before.
Speaking in the figure of the dining job executors: The job executors behave gently when they can’t get a sweet they want and wait until they can safely reach into the candy jar.
Practice: Configuration and Performance
Above we have shown that job acquisition backoff can reduce database load by avoiding unnecessary acquisition cycles. Two questions remain: Is this improvement noticeable in practice? How to find suitable backoff settings?
When tweaking job executor configuration settings, it is advisable to do this in a data-driven way. The following should be defined upfront:
- A scenario that resembles realistic workload; this also includes all parameters that are not optimized as part of the benchmark
- A metric of success, i.e. something that indicates whether one setting is better than another
- A parameter that is optimized
It is also possible to optimize multiple parameters, however in that case it is advisable to optimize one after the other to be able to attribute improvements to a specific parameter change. We define our benchmark as follows:
- Scenario
- 50,000 instances of a simple process with one asynchronous service task. The task simulates calling an external service by artificially waiting for a verying amount of time. We draw this time from a normal distribution with a mean of 80 milliseconds and a standard deviation of 25 milliseconds.
- A Postgres 9.4 instance using three cores of a 4 GHz machine serving as the engine database
- The Camunda Tomcat distribution in the versions 7.4.0-alpha1 and the current 7.4.0-SNAPSHOT
- The size of the job queue used by the execution thread pool is 100
- Metric of success
- Throughput: Measured by the overall duration to process all jobs
- Supplementary metrics: To understand the changes in throughput, we collect the database’s CPU usage and statistics of successfully and unsuccessfully locked jobs
- Parameters
- Number of cluster nodes
- Number of jobs to acquire
- Backoff settings
As the first step, we tune the number of cluster nodes until we operate our Postgres instance at full capacity. That level is reached with 5 nodes when there are only marginal improvements in throughput with more nodes due to the database operating with 100% CPU load.
Next, we see if we can improve the performance with the following settings:
- default alpha1 configuration: 3 jobs acquired per cycle; no backoff (baseline)
- default alpha1 configuration: 48 jobs acquired per cycle; no backoff
- backoff configuration – initial: 50 ms; maximum: 250 ms; increase factor: 2
- backoff configuration – initial: 70 ms; maximum: 350 ms; increase factor: 2
- backoff configuration – initial: 90 ms; maximum: 450 ms; increase factor: 2
Note that all of the backoff configurations imply acquiring 3 jobs initially and 48 jobs with the highest backoff. In terms of throughput, we obtain the following results:
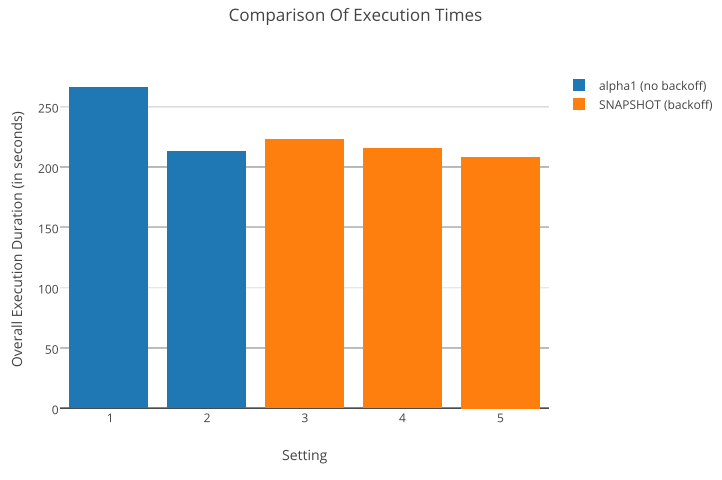
As settings 2 and 5 show the best performance, we notice that acquiring larger chunks of jobs in one acquisition cycle is beneficial in our scenario. Furthermore, we notice only a slight benefit of a configuration with backoff to one without. This can be explained by the way the alpha1 engine deals with the case that the job execution queue is saturated: In such a situation, the job acquisition thread itself begins executing jobs that cannot be submitted. This way, an uncontrolled backoff effect sets in and acquisition automatically becomes less frequent. In case the workload is more heterogenous than in our scenario, it may happen that the acquisition thread executes a rather long running job stalling execution resources that recover meanwhile by not acquiring new jobs. With the upcoming alpha2 release, we have changed this behavior such that the acquisition thread’s only responsibility is to acquire jobs.
This leads to the following conclusions:
- If you use the BPM platform in a high-load scenario where performance is important, consider tweaking the job executor settings.
- Before changing settings, define a suitable benchmark by a realistic scenario, a metric of success, and parameters that you are going to change.
- If you run the job executor on a single machine, the execution queue size and the number of jobs acquired per acquisition cycle are good parameters.
- If you run a cluster, the job acquisition backoff settings are good parameters.
- Backoff reduces the number of acquisition queries and job lock failures, freeing some of your database’s processing resources.
Background Reading and Resources
In order to try out the backoff configuration settings, you may wait for our upcoming alpha2 release or use a nightly SNAPSHOT build. For all the job executor configuration options have a look at our bpm-platform.xml deployment descriptor reference. For engine and job acquisition metrics, the user guide provides insight into which metrics are collected out of the box, among these the number of job acquisition cycles and job locking failures that were used in this blogpost.
